Image-Captioning Tactical Advisor Model (ICTAM)
1. Introduction
ICTAM was my first attempt at applying pretrained LLMs to tactical analysis and advisory tasks. This work was inspired by CICERO and LLMs play sc2. I primarily wanted to test the pretrained capabilities of image captioning models and see if they could make accurate tactical judgements with minimal supervised finetuning.2. Data Processing
My data pipeline consists of starcraft youtube video downloads from yt-dlp which feeds into image sampling and cropping using ffmpeg. I sample one image per minute (1/60 fps) as 1 frame should loosely describe the tactical state of the minimap for a minute although more sampling would be good. I crop the bottom left of the screen as that is where the minimap is. I then generate a .json caption file that stores a dictionary per image-caption pair. In order to enable tactical judgement evaluation, the captions were structured to start with "Winner. Followed by the rest of the caption."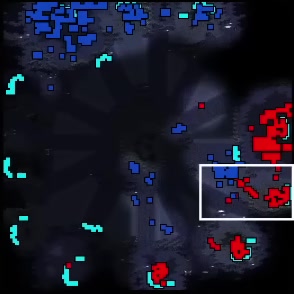
Sample Frame

Sample Caption
3. Training and Validation
I did an 80-10-10 train-val-test split on my image-caption pairs. I then trained the BLIPConditionalGeneration model with the HuggingFace Trainer. This model was trained with an image-conditioned autoregressive cross-entropy loss. What this means is that the model has a "vocabulary" of a large amount of tokens (30,000 for example) and after seeing an image and the tokens before, it assigns a probability distribution across all tokens in its vocab on what is most likely to be the next token in the sequence. During training the loss then compares the probability assigned to the "correct" token and optimizes as it wants the probability to be as close to 100% as possible.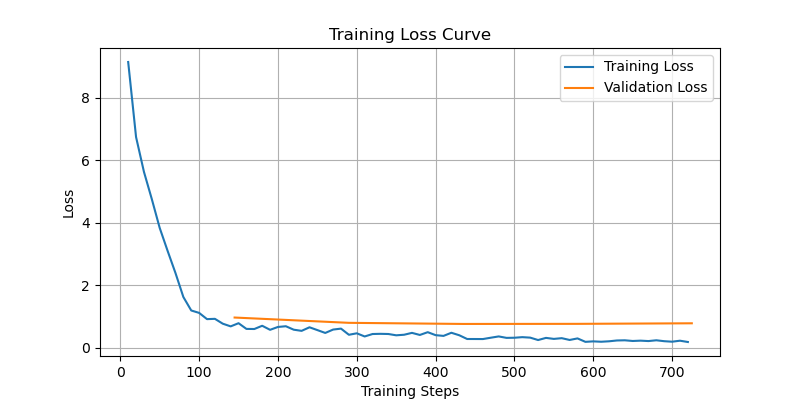
Train-Validation Loss Curves (validation only starts after the first epoch)
4. Evaluation
I evaluated the % of correct tactical judgement from BLIP by parsing the caption string, and creating a list of just the winner prediction before the ".". I then compared this list against the same list from the actual captions. ICTAM successfully identifies the "winning player color" 80% of the time across multiple test trials with the test dataset which ICTAM had not been trained on.
blip-base caption inference result

blip-finetuned caption inference result
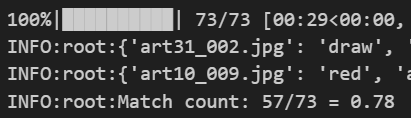
ICTAM Tactical Judgement Accuracy